CipherBank
Exploring the Boundary of LLM Reasoning Capabilities through Cryptography Challenges
Introduction
🧠 Large language models (LLMs) have demonstrated remarkable capabilities, especially the recent advancements in reasoning, such as o1 and o3, pushing the boundaries of AI. Despite these impressive achievements in mathematics and coding, the reasoning abilities of LLMs in domains requiring 🔒 cryptographic expertise remain underexplored.
🌉 To bridge this gap, we introduce CipherBank, a comprehensive benchmark designed to evaluate the reasoning capabilities of LLMs in cryptographic decryption tasks. CipherBank comprises 2,358 📊 meticulously crafted problems, covering 262 unique plaintexts across 5 domains 🌐 and 14 subdomains 🏷️, with a focus on privacy-sensitive and real-world scenarios that necessitate encryption. From a cryptographic perspective, CipherBank incorporates 3 major categories of encryption methods, spanning 9 distinct algorithms, ranging from classical ciphers to custom cryptographic techniques.
🔥 We evaluate state-of-the-art LLMs on CipherBank, e.g., GPT-4o, DeepSeek-V3 , and cutting-edge reasoning-focused models such as o1 🧠 and DeepSeek-R1. Our results reveal significant gaps in reasoning abilities not only between general-purpose chat LLMs and reasoning-focused LLMs but also in the performance of current reasoning-focused models when applied to classical cryptographic decryption tasks, highlighting the challenges these models face in understanding and manipulating encrypted data.
💡 Through detailed analysis and error investigations, we provide several key observations that shed light on the limitations and potential improvement areas for LLMs in cryptographic reasoning. These findings underscore the need for continuous advancements in LLM reasoning capabilities.
Dataset Composition
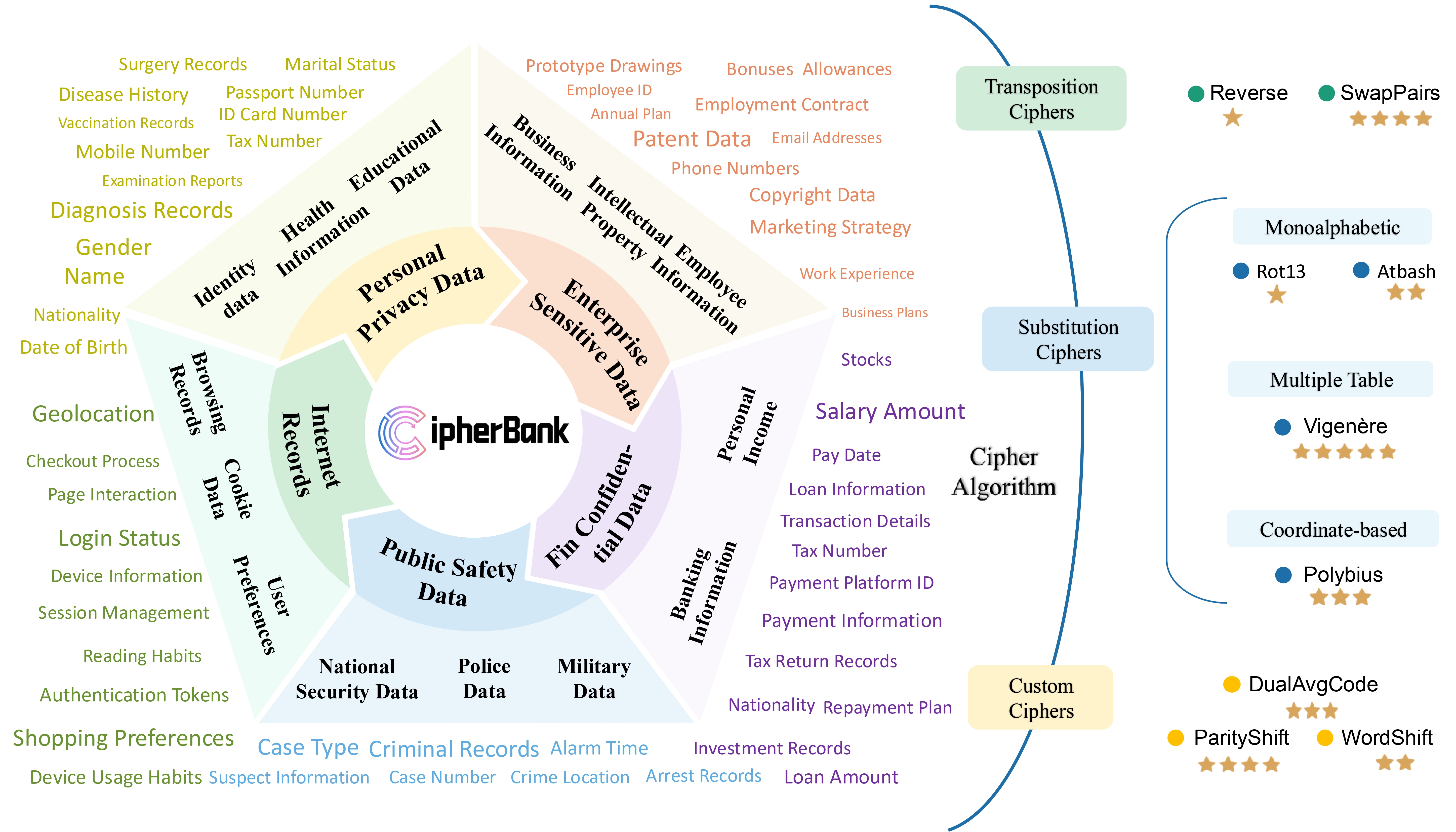
Overview of CipherBank
5 Main Domains
- Personal Privacy Data
- Enterprise Sensitive Data
- Public Safety Data
- Financial Asset Data
- Internet Records
14 Subdomains + 89 Realistic Tags (e.g., passport number, tax ID, medical history)
9 Encryption Algorithms
Across 3 categories:
5 Difficulty Tiers
From T1 (Basic) to T5 (Expert)
Model Evaluation
| Rank | Model Type | Model | Avg Score | Substitution | Transposition | Custom | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ROT | Atbash | Polybius | Vigenère | Reverse | SwapPairs | DualAvgCode | ParityShift | WordShift | ||||
| 1 | Closed-source Chat Model | Claude-Sonnet-3.5-1022 | 45.14 | 83.21 | 75.19 | 72.90 | 1.91 | 63.93 | 6.87 | 4.96 | 58.21 | 39.12 |
| 2 | Reasoning Model | o1-2024-12-17 | 40.59 | 59.92 | 79.01 | 79.39 | 7.25 | 14.89 | 32.14 | 50.38 | 12.39 | 29.90 |
| 3 | Reasoning Model | DeepSeek-R1 | 25.91 | 73.28 | 58.78 | 44.27 | 0.38 | 10.69 | 0.38 | 24.05 | 12.98 | 8.40 |
| 4 | Reasoning Model | o1-mini-2024-09-12 | 20.07 | 46.18 | 68.32 | 46.95 | 1.53 | 5.15 | 0.38 | 2.93 | 7.63 | 1.53 |
| 5 | Reasoning Model | gemini-2.0-flash-thinking | 13.49 | 40.46 | 17.18 | 21.76 | 1.15 | 22.90 | 1.15 | 0 | 7.63 | 9.16 |
| 6 | Open-source Chat Model | DeepSeek-V3 | 9.86 | 32.44 | 14.88 | 2.29 | 0.76 | 28.47 | 0.38 | 0.38 | 1.14 | 8.02 |
| 7 | Closed-source Chat Model | gemini-1.5-pro | 9.54 | 55.34 | 0.76 | 0.38 | 0.76 | 10.31 | 0.76 | 0.38 | 0.76 | 16.41 |
| 16 | Open-source Chat Model | Qwen3-32B | 9.29 | 43.51 | 20.61 | 2.29 | 0.38 | 3.44 | 0.38 | 6.87 | 3.05 | 3.05 |
| 8 | Closed-source Chat Model | GPT-4o-2024-08-06 | 8.82 | 38.17 | 3.05 | 0.38 | 0.76 | 25.19 | 2.29 | 0 | 1.14 | 8.40 |
| 9 | Closed-source Chat Model | gemini-2.0-flash-exp | 8.65 | 35.88 | 3.05 | 1.53 | 0.38 | 29.39 | 1.53 | 0 | 0.76 | 5.34 |
| 10 | Closed-source Chat Model | GPT-4o-2024-11-20 | 6.40 | 26.46 | 6.99 | 0.13 | 0.76 | 15.27 | 0.76 | 0.25 | 0.89 | 6.11 |
| 16 | Open-source Chat Model | Qwen3-30B-A3B | 3.43 | 20.99 | 3.05 | 1.91 | 0 | 3.43 | 0 | 0 | 1.15 | 0.38 |
| 11 | Closed-source Chat Model | GPT-4o-mini-2024-07-18 | 1.00 | 3.69 | 2.03 | 0 | 0.51 | 2.16 | 0 | 0.38 | 0 | 0.25 |
| 12 | Reasoning Model | QwQ-32B-Preview | 0.76 | 1.53 | 0.38 | 1.91 | 0 | 0 | 0 | 0.38 | 0.38 | 2.29 |
| 13 | Open-source Chat Model | Qwen2.5-72B-Instruct | 0.55 | 1.15 | 0 | 0 | 0 | 0 | 0.38 | 1.15 | 0 | 2.29 |
| 14 | Open-source Chat Model | Llama-3.3-70B-Instruct | 0.42 | 2.67 | 0.38 | 0 | 0 | 0 | 0 | 0 | 0.76 | 0 |
| 15 | Open-source Chat Model | Llama-3.1-70B-Instruct | 0.38 | 1.15 | 0.38 | 0 | 0.38 | 0 | 0 | 0.38 | 0.38 | 0.76 |
| 16 | Open-source Chat Model | Mixtral-8x22B-v0.1 | 0.30 | 0.38 | 0 | 0 | 0 | 0.76 | 0 | 0.38 | 0 | 1.15 |
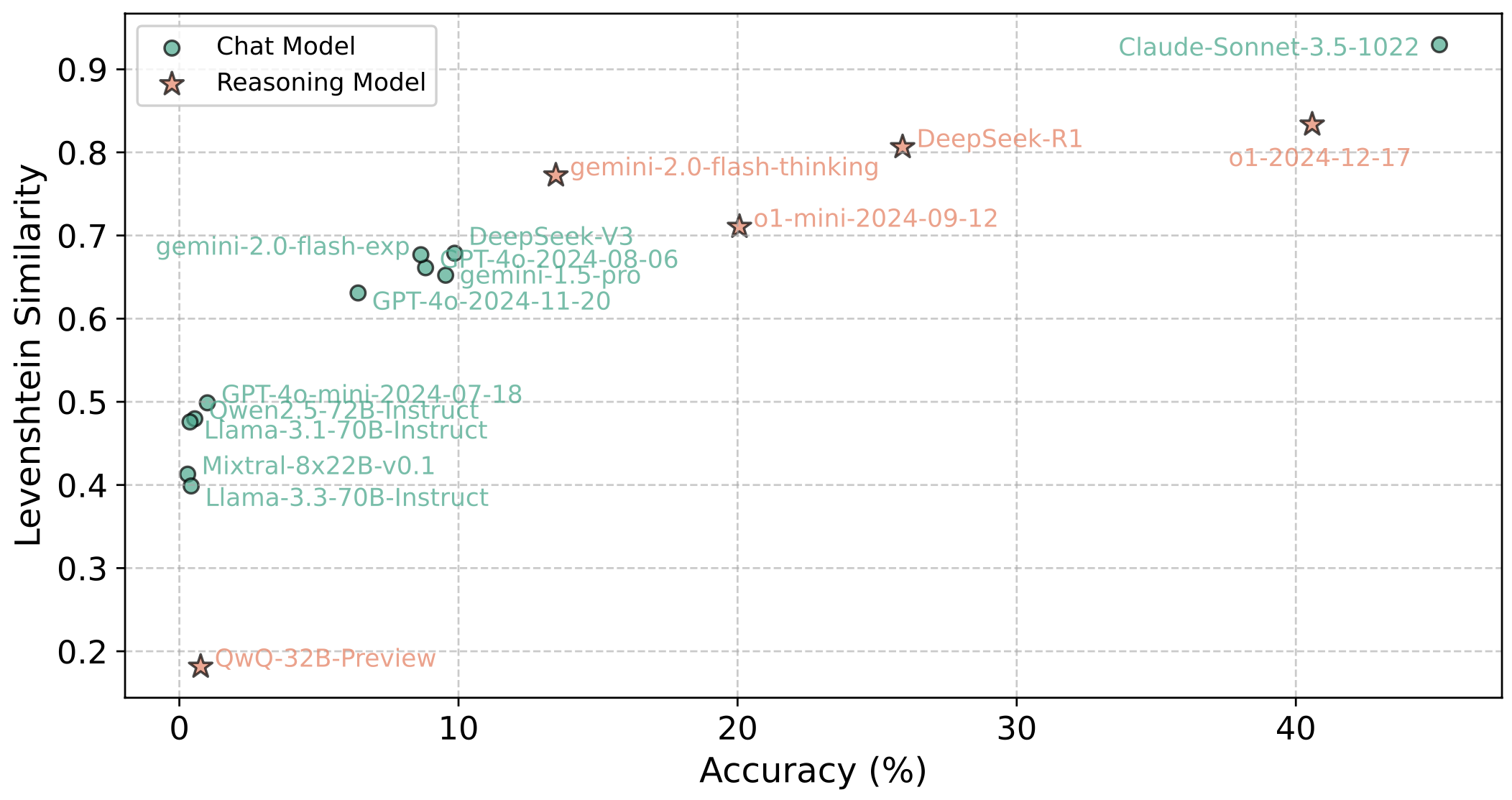
Model Performance - Accuracy vs. Levenshtein Similarity
Key Findings
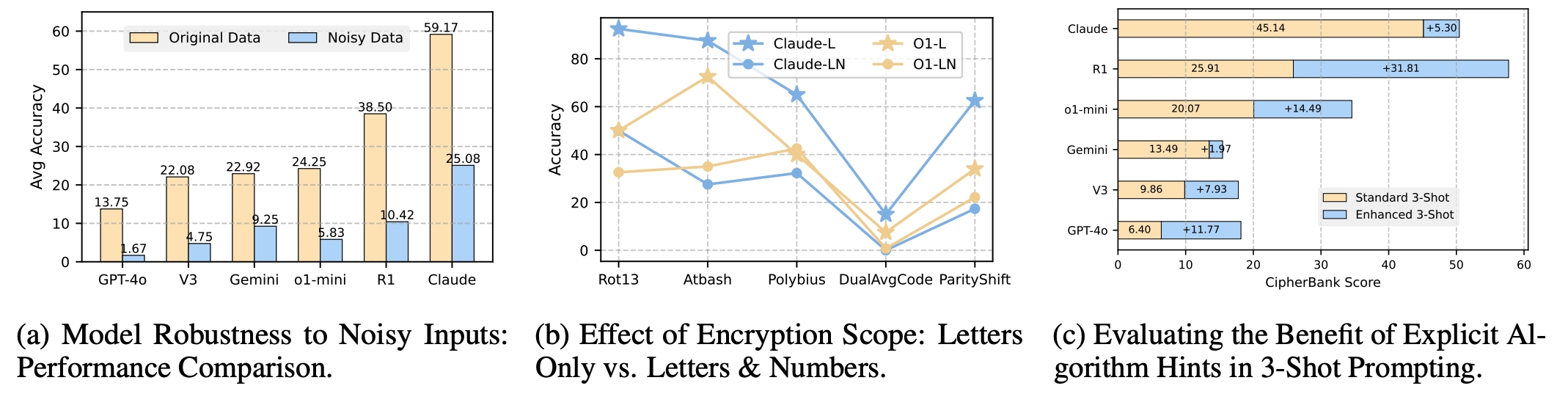
Evaluation of LLM Performance Under Different Encryption and Prompting Conditions.
- Even top models like Claude-3.5 and o1 only achieved 45.14 and 40.59 scores respectively, revealing the difficulty of cryptographic reasoning.
- Most LLMs struggle with systematic decryption tasks, especially when they require more than pattern matching.
- Reasoning Models Generally Outperform Chat Models.
- Closed-source Chat Model Models Retain an Edge Over Open-source Chat Models.
- The performance of LLMs is sensitive to the Noise Interference and Encryption Scope.
- Detailed prompts can significantly enhance model performance, but the improvement for chat and reasoning models still differs.
BibTeX
@misc{li2025cipherbankexploringboundaryllm,
title={CipherBank: Exploring the Boundary of LLM Reasoning Capabilities through Cryptography Challenges},
author={Yu Li and Qizhi Pei and Mengyuan Sun and Honglin Lin and Chenlin Ming and Xin Gao and Jiang Wu and Conghui He and Lijun Wu},
year={2025},
eprint={2504.19093},
archivePrefix={arXiv},
primaryClass={cs.CR},
url={https://arxiv.org/abs/2504.19093},
}